Character Encodings, Null Bytes, and Changing Appetites

If you do find yourself staring at such a screen of random characters whatever you do don’t panic! You haven’t entered the matrix. You’ve simply come across the work of a developer who most likely didn’t have an understanding of character encoding! And today, in 2015, with more than 7 billion persons speaking just over 7000 languages character encoding is a very important concept for any developer to at least have a high-level understanding.
Computers are dumb
While there may be over 7000 languages spoken across the globe1, our fancy computers, stacked with gigabytes of RAM, terabytes of storage capacity, and capable of executing billions of calculations per second only speak one - binary.
1 or 0, true or false, on or off. Binary is really just a way for us humans to represent electrical signals computers use to communicate. Your computer has no idea, nor cares, what a number, letter, or symbol is - all it truly knows is on or off.
Just because my knowledge of Japanese is non-existent doesn’t mean I can’t hold a conversation with a Japanese speaker. On my trip to Tokyo I could always pack an English - Japanese dictionary and translate word-for-word what I’d like to say2. Encoding schemes or encodings work the same way, translating bits to characters just as my dictionary translates English to Japanese. And with this, let’s dicuss our first encoding - the American Standard Code for Information Interchange or ASCII. ASCII encodes 128 characters into 7-bit binary integers (8 bits total, with most significant bit always 0)
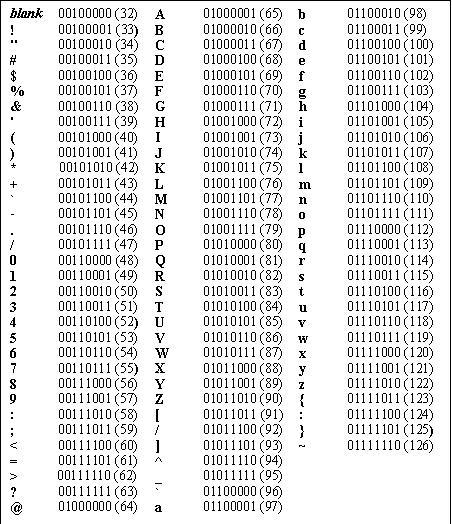
ASCII Table containing all printable characters (32-126).
This means that ASCII uses every combination of 7 bits to represent 2^7 or 128 characters. The first 32 characters in the ASCII table are control codes for things like space, carriage return, escape, etc, while characters 32-126 (127 is Delete) are for printable characters - letters, digits, punctuation marks, and a few more symbols. Just about every key on your keyboard! This is great and worked really well for quite some time. Of course, until you remember that we learned there are around 7000 languages in the world with more than 7 billion people speaking them - over 3 billion of which are online3! Clearly we’re going to need more encodings.
Hello Unicode
Soon enough someone came to this great realization and set out to create a system to represent any character in the world. 7 days later Unicode was born (total lie, I actually have no idea how long Unicode took to develop. Most likely much longer than 7 days). But to throw a wrench in our whole discussion I have to tell you that Unicode actually isn’t an encoding at all, but rather a table of code points mapped to characters. To encode Unicode into bits we need an encoding, of which there are many. Since Unicode maps just about all of the characters in the world to code points there’s no way every single character could be represented with just 8 bits. Some might need 16 or even 32. This is why we have variable length encodings, many of which you’ve probably seen at one point or another - exmaples include UTF-8, UTF-16, or UTF-32. These encodings are called variable length because, well, each character representation’s bit string varies in length. Let’s take UTF-8 for example. If a character can be represented using only 8 bits (ASCII) UTF-8 will use only 8 bits, but when a character requires more it can allocate 16 bits. UTF-16 is similar, however the smallest amount of bits it will use is 16 and will use all the way up to 32. For this reason UTF-8 maps 1:1 to any ASCII characters which also use 8 bits, while UTF-16 will use nul bytes when representing shorter character codes.

Marc Andreesen said that software is eating the world. While it might be
devouring the world, this beast has no doubt proven a huge craving for select
industries, while nibbling at others over the years. If we had the chance to
dine with this software creature’s family, commercial real estate would be the
meat plate you grabbed on the way, only to find out the majority of the family
is vegetarian - a few are extremely stoked, but the rest will stick with their
greens. Not because they have anything against meat, simply because no one has
ever cooked them a medium rare New York strip steak. This is the exact product
we’ve been busy buiding at VTS, taking advatnage of modern technologies to
craft tools that push the limits of how commercial real estate companies manage
their data. We’re driving an industry held back by old ancient technologies
into the future. This means that while we’re able to pick what we believe to
be arguably some of the best tools for the job, Ruby on Rails handling our
backend APIs, Angular.js for a native-like user experience, Redis for quick
caching, etc. we don’t get to pick the stacks our clients have chosen nor the
ways we interface with their data. Many times the best representation of their
data we are able to work with is a collection of very large CSV files exported
from any number of services. These files contain characters, no doubt, and
since we’ve learned that a computer has no idea what a character is, we can be
sure that the program exporting this data chose some encoding scheme to
translate these bits to letters. The most important thing when working with
any file containing characters, especially one you’re trying to parse and
transform is to always know what encoding it was encoded in. The thing is, it
can be pretty difficult so know precisely what encoding a program uses, even
when looking at the bit level. With our current tools we know we can always
rely on our csv reader to seamlessly handle UTF-8 encoded 8-bit-clean data, but
can run into problems when working with anything using 2 bytes to represent
characters which will encode the non-necessary bytes as nul - encodings like
UTF-16, UTF-32. The simplest way to deal with this is the point I’ve been
trying to drive home all along - know your encoding! While this isn’t always a
bullet-proof solution it should solve 99.9% of your problems when working with
characters. We’ll save the 0.01% of problems and solutions for another blog
post. Many times the hardest part of problem solving is finding the right
questions to ask. However, the next time you’re working with any file
containing characters and your terminal begins attacking you with nul byte
exceptions, you already know the two most important questions:
“What encoding did this document use?”
“what encoding does my reader expect?”
And in case you were wondering, I just got back from dinner with the software family. Turns out they’re finally realizing the enormous opportunities in Commercial Real Estate Technology - the same realization VTS had a few years ago. Lucky for us, we’re not the only ones seeing this huge need for innovation. With OpenView Venture Partners leading our $21 million Series B, we’re rapidly expanding the already ~1.5 billion SqFt managed on VTS. And yes, we’re hiring. :)
Feel free to reach out with any questions/comments about topics discussed in this post! @buildingvts @askwheeler
For more great articles on character encoding be sure to checkout the following two blog posts that really solidified many of these encoding concepts for me.