So You Want to Build a Search Engine
I tend to keep posts about things I work on outside of the classroom - which makes sense because 99.9% of the cool technical projects I work on are outside of school. However, at work I recently found myself using some really rad ideas I learned in my data structures class to find a solution to optimizing a program that will be running on our production platform - which means it needs to be fast - not seconds, but hundredths of a second. I’ll cover this solution in my next post. Anyways, I figured if this knowledge was an enormous help to solving my problem, other people could find it useful or just plain cool.
We worked on a ton of cool projects throughout the course, but one of my favorites was for sure a mini search engine we built, similar to how a service like google works. Given a directory containing just over 2500 wikipedia articles, write a program to allow users to type in some keywords and get the 3 most relevant articles in our “database”. I’ve been wanting to write a post on this for a while simply because I thought it was really cool and can help you think about all the ways you could solve other problems. These first two sections (Arrays, Linked Lists) go over some of the benefits and drawbacks to each respective data structure, so feel free to skip them if you already have a solid understanding of each, but they for sure act as a solid primer for the discussion about actually building the search engine.
Arrays
Our friend John’s birthday is coming up and he wants this to be the best party anyone has ever seen. There’s only one problem. John has put off the event planning until the last minute and really needs some help if the party is going to be a success. He knows you are a software developer, not only because he’s a great friend of yours, but also because any time you get drunk you love to talk about your most recent projects and even though he never understands what the hell you’re talking about, he’s pretty much an isomorphic javascript expert without even knowing what that means. John gives you a call and tells you he’s going to need a program that can store a guest list of people attending his party. His guest list has needs to be able to do 4 things.
-
Add a new name - someone RSVPs
-
Look up a name - to make sure they’re on the guest list at the door
-
Delete a name - in case someone can’t make it after rsvping
-
Print out all names - he will need to send thank you notes to every guest
For simplicity let’s say he also knows that the venue has a maximum capacity of 10 persons.
There are countless ways to store the data in our GuestList application and one of the first ways that comes to mind is an array.
Knowing our guest list won’t exceed 10, we instantiate an array with a length of 10.
String[] guests = new String[10];
guests
{ null, null, null, null, null, null, null, null, null, null }
We can have a simple counter that increments every time we add a new name to keep track of what index is currently available to insert that name.
public static void insert(String name) {
guests[next++] = name;
}
At this point it looks like some guests are rsvping and we can start adding them to the list.
insert("foor")
insert("bar")
insert("baz")
> guests
{ foo, bar, baz, Eich, Wozniak, tenderlove, Hartl, Katz, Stallman, Torvalds }
Before we know it is the night of the party and our guests are starting
to show up. Since we implemented the isOnList() feature we can look up a
guest name and see if they are indeed on our list. It simply iterates through
the array and sees if any elements match the name.
public boolean isOnList(String name) {
for(int i = 0; i < guests.length; i++) {
if(guests[i].equals(name)) {
return true;
}
}
}
Looks like foo is first to arrive so let’s run our program and see if she is indeed on the list.
isOnList("foo")
true
Cool, foo is on the list and the program only took .01 seconds to run since it found foo’s name in the first slot in our array.
Now, Stalman arrives (yes Stalman with 1 “L”). We check to see if Stalman is on the list,
isOnList("Stalman")
false
An imposter! Our program tells us: no, Stalman is not on the list and this must be an imposter impersonating the almighty father of free software (we should have known better he didn’t have his backpack full of Free Software Foundation swag). In order to give us an answer our GuestList application had to check every single element in our array, which took .10 seconds. This is 0(n) time complexity and while it isn’t a huge problem for John’s small get together, what if we had an Array of 100,000 names. At this rate each guest we turned away would cause a search of the entire array, holding the line up for ~16.7 minutes. And an Array of 1,000,000 names. Each turned away person would hold us up for nearly 2.8 hours!
Here’s our first major problem with arrays - there’s no way to find some data without searching the entire array!
With this being said there is one reason to not give up on our good friend the array. If we know the index at which some data is stored he is lightning fast at retrieving it. In nerd terms he can return our data with 0(1) or constant time complexity.
What if we want to delete an element? We can’t just remove elements. All we can do is move elements to different indexes and we would do exactly that. We would find the element we want to delete and then shift every single element after that index over 1 index and decrement our next counter by 1. Clearly this is not very efficient and a total pain in the ass. And if we wanted to add more than 10 names? We would find outselves creating an array of twice the size, iterating through the original and one-by-one copying the elements to the new, larger array.
A more efficient data structure would address these two problems. It would allow us to easily delete elements, as well as add more elements without having to create an entire new structure and reindex everything.
Linked Lists
Linked Lists solve just that. A linked list is exactly what it sounds like. It is a collection of objects, we call Nodes, that store some type of data and are connected by pointers that pint to one of two things.
-
another Node
-
null

Let’s take for example Node A seen above. Node A has two attributes:
-
data
-
next
This time data will hold the name of our guest and next will either return a
Node or null. In this case if we call A.next() it will return B. Calling
B.next() will return C. And D.next() will return null, telling us we are at
the end of the list. This structure makes it extremely simple to traverse. We
could set a pointer to point at A and then that pointer can move along the list
until it gets to null at which point we’ve checked every name;
Node current = A;
while(current != null) {
System.out.println(current.data);
current = current.next;
}
What if we want to add a new name to our list? Easy! Just keep stepping through the list until the current node’s next returns null and set currentNode.next to point to a new node. This shortest way to implement this is recursively as so:
public static void insert(Node n, String name) {
if(n.next == null) {
return new Node(name);
}
node.next = insert(n.next, name);
}
While this the current node.next() isnt null our function recursively
sets node.next() to whatever insert(node.next, name) returns. Once node.next
== null it returns a new Node with our supplied name and therefore just sets
the last node in the list to point at this new node. (If you’re not familiar
with how recursive functions and stack frames work, it is definitely something
to look into as there’s some pretty cool stuff you can do with them).
This solves our problem of not wanting to have to worry about adding elements and running out of room as happens with an array.
Onto the second problem of wanting to delete elements. This is actually even easier. Since we are just working with nodes and pointers the easiest way to delete a node is to simply take the previous node and point it at the node after the one we want to delete, essentially routing around it.
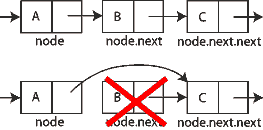
Great! Linked Lists solve our two problems with arrays. We can add as many elements as we’d like to and we can delete elements extremely easily. The only problem is that we have lost the one thing arrays are really good at - lightning fast lookup if we know where data lives. Since we have no way to reference a node without chaining through the whole list, we can’t directly look up some data as we could in an array.
If only we could get the lightning fast speed of arrays with the flexibility of linked lists…
Hash Tables
Hash tables combine the speed of Array lookup, with the flexibility of Linked Lists to provide us with a near perfect data structure. A hash table is an Array, but instead of each index holding our data it holds a pointer pointing to a linked list (we call these buckets) of data. Take a look at the hash table below. The numbers on the left represent the array indexes, and the arrows are pointers pointing to items that have been inserted into the table. In an Array we just push items in since we don’t need to know which index to find them at. Hash Tables, on the other hand are used when we want to (very quickly) be able to look up a value without having to iterate through an entire structure. This means that the same function we use to determine which bucket or index to insert it into is, will be the same function we use to find which bucket the data lives in.
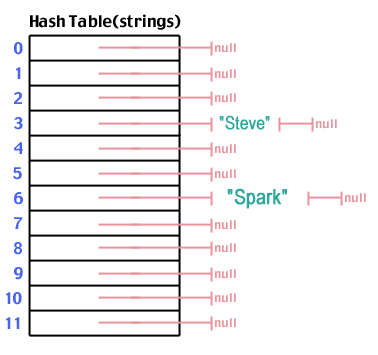
This is where the hashing function comes into play (hence the name hash table). Hashing is a method to turn a string of characters into a key or value that represents the original string. So, we need to pick some sort of key that we will use for the data we’re storing in the table. If you’re storing data about people you could use a first name, last name, social security number (probably not best idea lol), anything that can identify the object. In our case we have a database full of Articles so we’ll use each article’s title. This will determine where to put the data, and we can use the same method to find where we put that data.
public int hash(String x) {
char ch[];
int SIZE = 10;
ch = x.toCharArray();
int i, sum;
for(sum = 0; i = 0; i < x.length(); i++) {
sum += ch[i];
}
return sum % SIZE;
}
This hash function starts by splitting the string into a char Array, so
“Alex” would be split into ['A','l','e','x']. It then iterates over the array,
converts each character to its respective ASCII value and sums them. (97 + 108 + 101 + 120 = 394) We mod this value by the size of the array, so that it will
always return a valid index for the array (integer between 0 and array.length -
1). 394 % 10 = 4 So we put this value in the bucket at index 4. If two
values hash to the same value then we just add the object to the end of the
linked list of that bucket. When we want to find an item in the table we use
the same hash function, which will, once again, return the index to the bucket
it is located in with a time complexity of 0(1).
Building our search engine
The first thing we’ll want to do is store each Article in our hash table - hashing each title to determine which bucket to place them in. With this knowledge alone our program can allow users to type in an exact title and the search engine can find it in 0(1).
Let’s say we have an article with the title “How to Code”. When we inserte the file the title is hashed to ‘7’ and stored in the bucket at index 7. Now finding the article is really easy, we just use the same hash function. The user enters “How to Code”. This value gets hashed and once again returns 7, it checks bucket 7 and finds an Article with the title “How to Code” and returns this to the user. Epic, looks like the user can now learn to code!
But we’re not building an application where users need to remember the exact name of an article. We’re building a search engine. A user should be able to type in some keywords and get the 3 most relevant articles in our database matching these keywords - just like Google.
Step 1:
Every Article is hashed and inserted into the table. We now have a table consisting of 2513 articles.
[ 0 ] -> {title: “Ruby is Fun”, body: “ …” }
[ 1 ] -> {title: “Javascript is Cool Too”, body: “ …” }
[ 2 ] -> {title: “Node: for hipsters”, body: “ …” }
[ 3 ] -> {title: “Ajax”, body: “ …” }
[ 4 ] -> {title: “Catchy Title”, body: “ …” }
.
.
.
[ 2512 ] -> {title: “haskell: for dummies”, body: “ … ”}
The user inputs some keywords, let’s say “100 reasons java sucks”.
The user input string is preprocessed. Our program downcases every character and removes anything except integers, letters, and spaces. The string is then parsed and a vector is created for each keyword and inserted into a new hashtable that we’ll call a keyWordsTable.
Let’s take two strings:
A: "100 reasons ruby is better than Java"
B: "100 reasons java sucks"
term freq A freq B
[ 100 ] { 1 , 1 }
[ reasons ] { 1 , 1 }
[ ruby ] { 1 , 0 }
[ java ] { 1 , 1 }
[ is ] { 1 , 0 }
[ better ] { 1 , 0 }
[ than ] { 1 , 0 }
[ sucks ] { 1 , 1 }
Combining these gives us two vectors:
A: [1, 1, 1, 1, 1, 1, 1, 0]
B: [1, 1, 0, 1, 0, 0, 0, 1]
We can then use the following formula to calculate their cosine similarity - ranging from 0 (no similarity) -> 1 (perfectly similar).

Plugging in our numbers reveals a cosine similarity of .76.
These two strings are pretty damn similar, so this value makes sense intuitively.
This is done for every artcicle title, comparing it with the user input keywords. Cosines greater than 0 are inerted into a Max Heap, which preserves articles in descending order from the front - based on cosine values.
e.g. adding example articles into Max Heap as they are processed
[{title: "java sucks", cosine: ".6"}, {"java really sucks", cosine: ".8"},
{"java could be worse", cosine: ".9"}]
…inserting one more with a cosine of .7 will preserve the descending order:
[{title: "java sucks", cosine: ".6"}, {title: "how java could be better", cosine:
".7"}, {"java really sucks", cosine: ".8"}, {title: "java could be worse", cosine:
".9"}]
Once every article has been processed we simply return the 3 articles at the front of the heap - these will be 3 most relevant articles due to nature of the Max Heap keeping articles stored in descending order from front to back by cosine similarity. If there aren’t 3 articles, since possible no 3 articles had a cosine similarity > 0.0 then the search engine tells the user that it couldn’t find any results matching their search.
(Feel free to reach out if you want the source code for this, had to take it off Github because my professor thinks “Github is the enemy”)